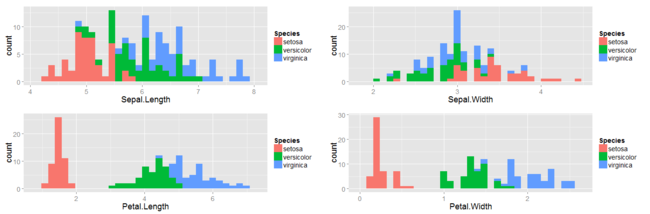
Gradient Descent Algorithm for Linear Regression
For this exercise I will use the data-set from this blogpost and compare the results to those of the lm() function used to calculate the linear model coefficients therein.
To understand the underlying math for the gradient descent algorithm, turn to page 5 of these notes, from Prof. Andrew Ng.
Here’s the code that automates the algorithm:
alligator = data.frame(
lnLength = c(3.87, 3.61, 4.33, 3.43, 3.81, 3.83, 3.46, 3.76,
3.50, 3.58, 4.19, 3.78, 3.71, 3.73, 3.78),
lnWeight = c(4.87, 3.93, 6.46, 3.33, 4.38, 4.70, 3.50, 4.50,
3.58, 3.64, 5.90, 4.43, 4.38, 4.42, 4.25)
)
X<-as.matrix(alligator$lnLength)
X<-cbind(1,X)
y<-as.matrix(alligator$lnWeight)
theta <- matrix(c(0,0), nrow=2)
alpha <- 0.1
for(i in 1:100000){
theta_n<-theta-alpha*(t(X)%*%((X%*%theta)-y))/length(y)
theta<-theta_n
}
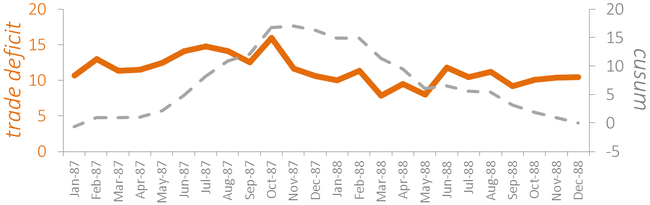
Here’s the output of the gradient descent...